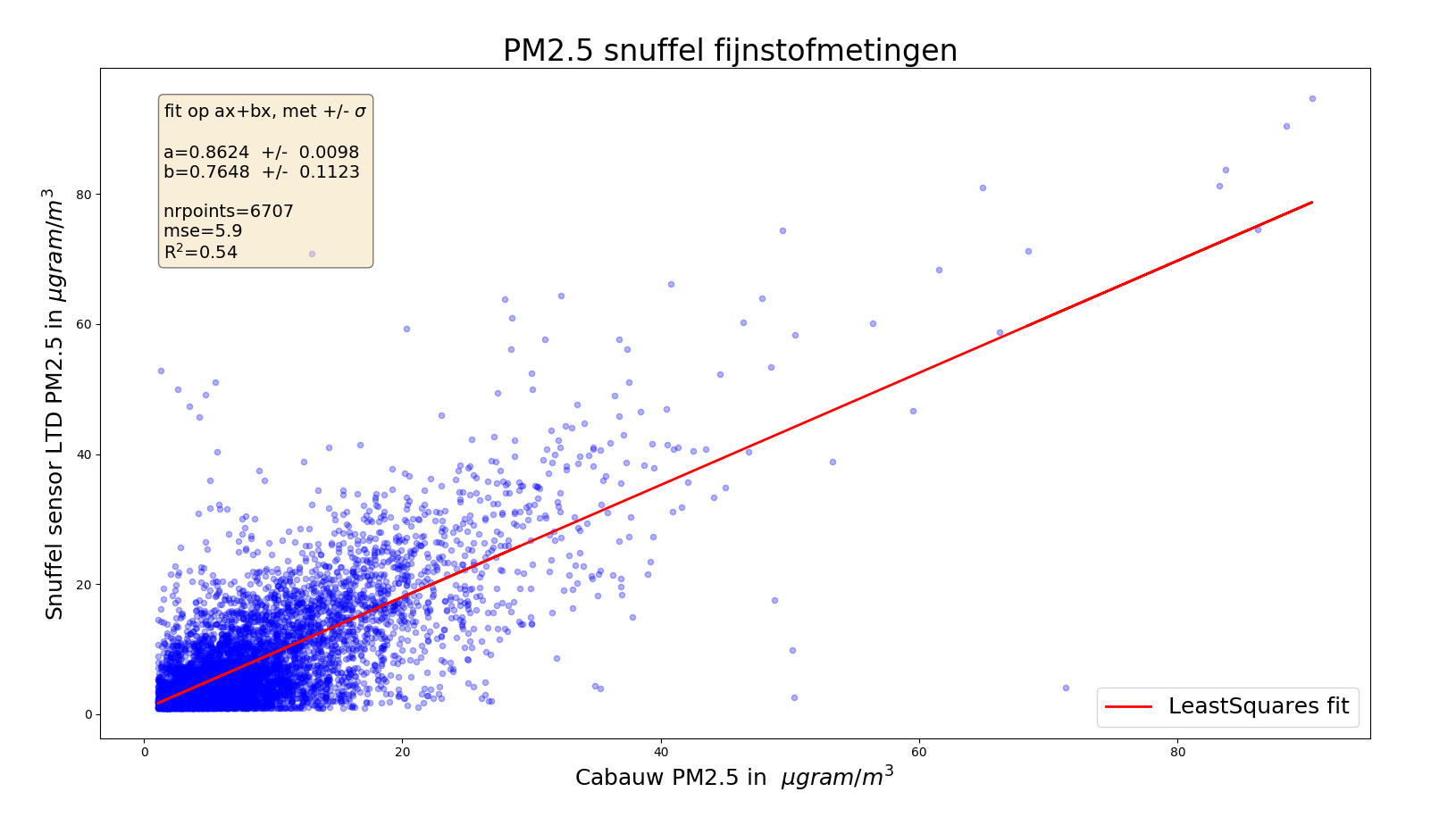
We analyseren figuur 5d (Snuffelfiets PM2.5 vs RIVM Cabauw) van het al eerder aangehaalde snuffelfiets artikel.
Tot ons genoegen kunnen we het plaatje zelf reproduceren (met de ter beschikking gestelde openbare data) en vinden dezelfde correlatiewaarde als in het artikel staat:
Een bekende facor die meetwaardes beinvloedt is de relatieve luchtvochtigheid.
De onderzoekers hebben er expliciet voor gekozen om deze niet mee te nemen
Helaas kunnen wij die niet zelf toevoegen omdat er in de beschikbare data geen datumtijd beschikbaar is.
Wat wel opvalt is dat de lage meetwaardes veel vaker voorkomen dan de hogere.
Op zich niet zo verwonderlijk, want het fijnstofgehalte is vaker laag dan hoog.
De correlatie waarde met Pearson is 0.73, wat op zich niet heel hoog is.
Gebruiken we andere methodes (Spearman, Kendall) dan valt de correlatiegraad lager uit.
Dat de meetwaardes niet zo uniform verdeeld zijn, brengt toch wat ongemakkelijke jeuk teweeg,
daarom gaan we rigoreus aan de slag:
1) we gooien alle waardes onder de 10 ugram/m3 weg
2) we ronden alle overblijvende Cabauw waardes af op gehele getallen
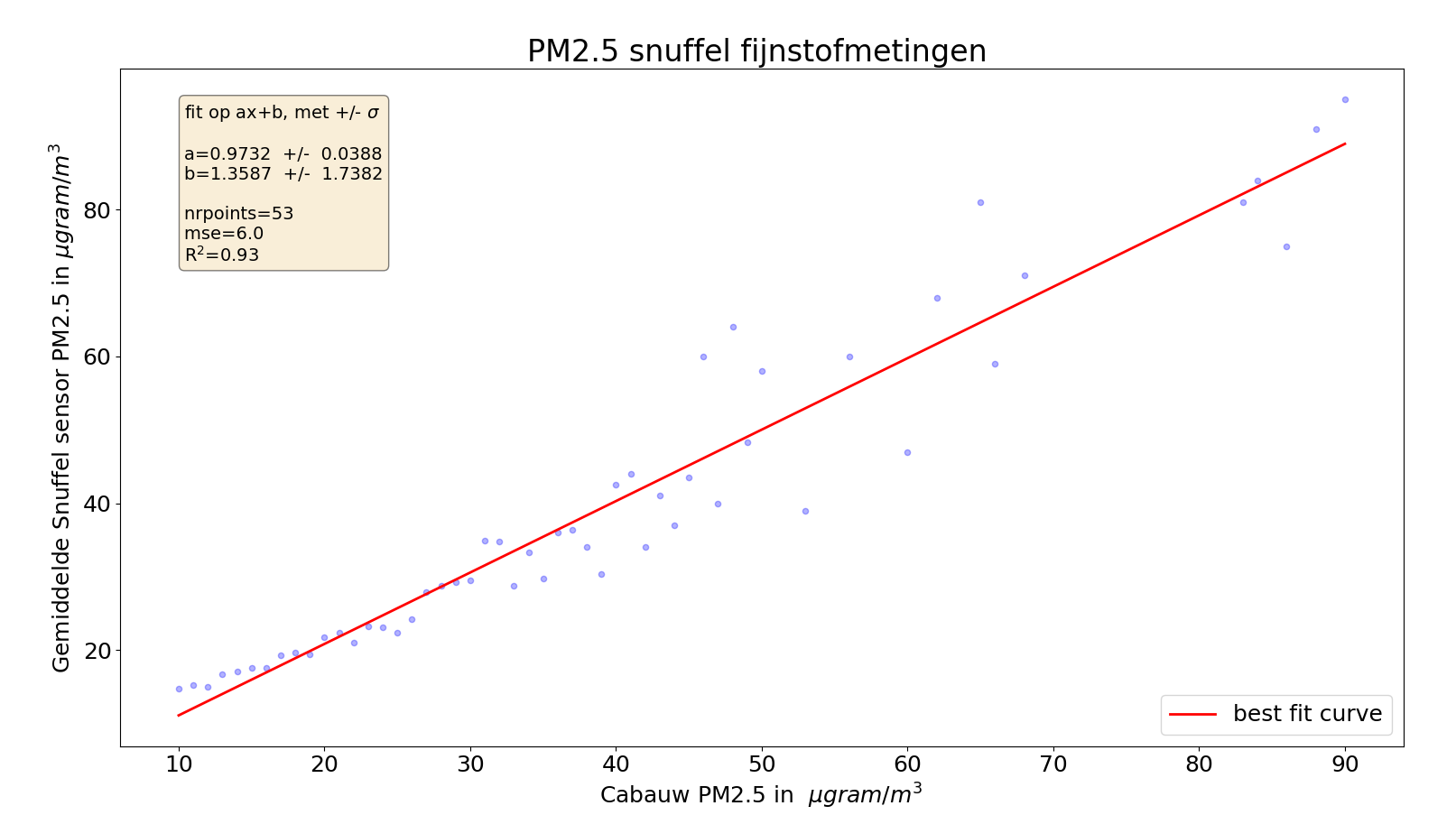
3) bij elk Cabauw getal nemen we het gemiddelde van de snuffelfiets waardes in die "kolom"
Met ons vertrouwen op de wet van de grote getallen, komt er een mooi correlerend plaatje uit:
De gemiddelde fout neemt niet heel erg sterk af, wat maar weer aangeeft dat mean squared error vaak een betere maat is dan (Pearson) correlatie.
Een interessante aanname is dat er in dit paper een eis gesteld wordt aan de spreiding van
fijnstofwaardes over de utrechtse stations voordat kalibratie toegepast wordt.
De standaarddeviatie mag maximaal 15% zijn van het gemiddelde van de Utrechtse stations.
Geen onterechte eis, omdat het hier een sterk locaal experiment betreft.
Maar het stelt wel de interessante vervolgvraag hoe vaak dit gebeurt of wat of de oorzaak
zou kunnen zijn van het uiteenlopen van meetwaardes naastgelegen RIVM stations.
Dit alles verandert niets aan de conclusie van de paper dat “de bijdrage van verkeer aan PM2.5 fijnstofgehalt, is orde 2 ug/m3 is” en dat er wel degelijk goede en foute routes bestaan, (zie Figuur13 en 14, waarbij ik vind dat de kleurcodering wel een zeer niet lineaire indeling kent met rood van 2.7 tm 72 ug/m3)