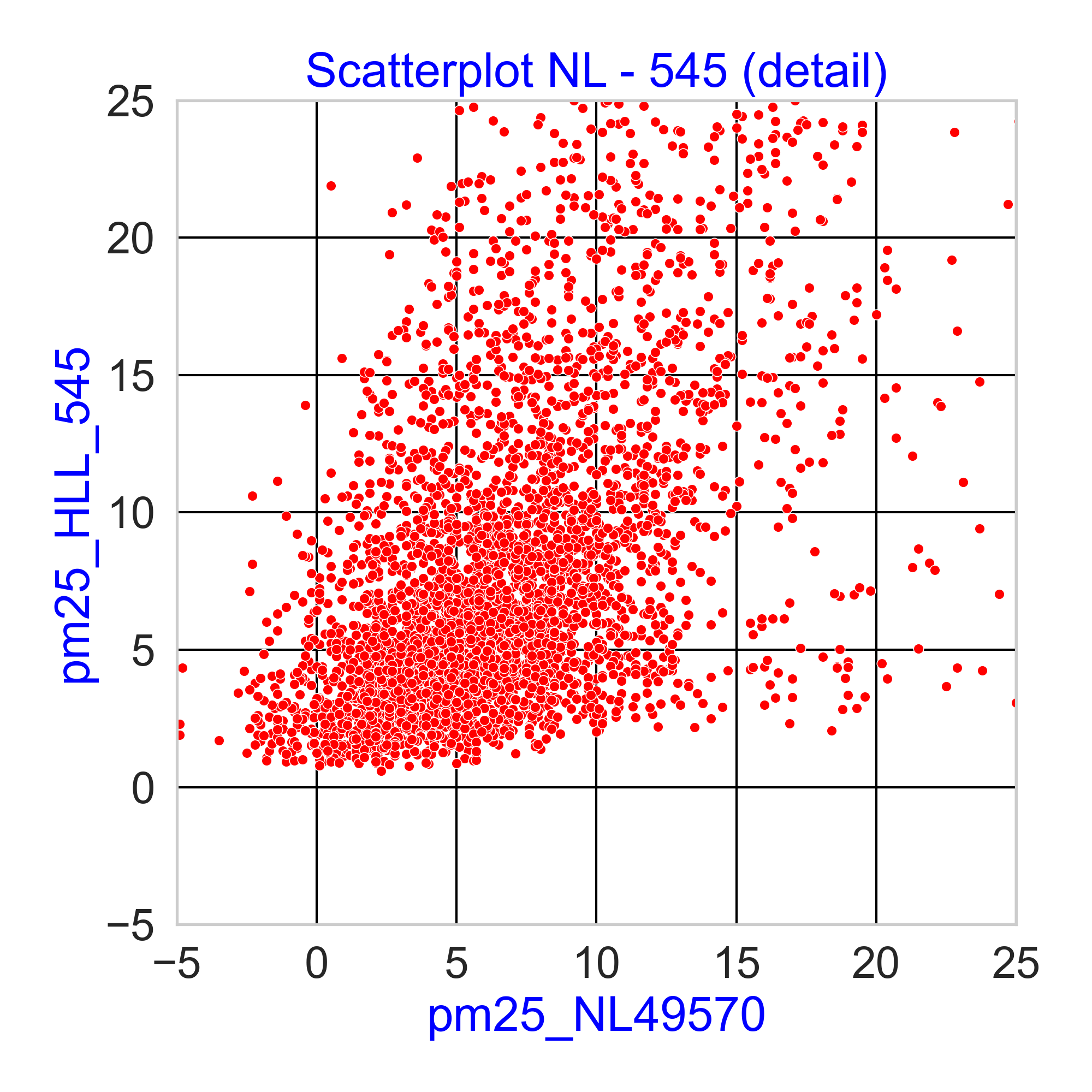
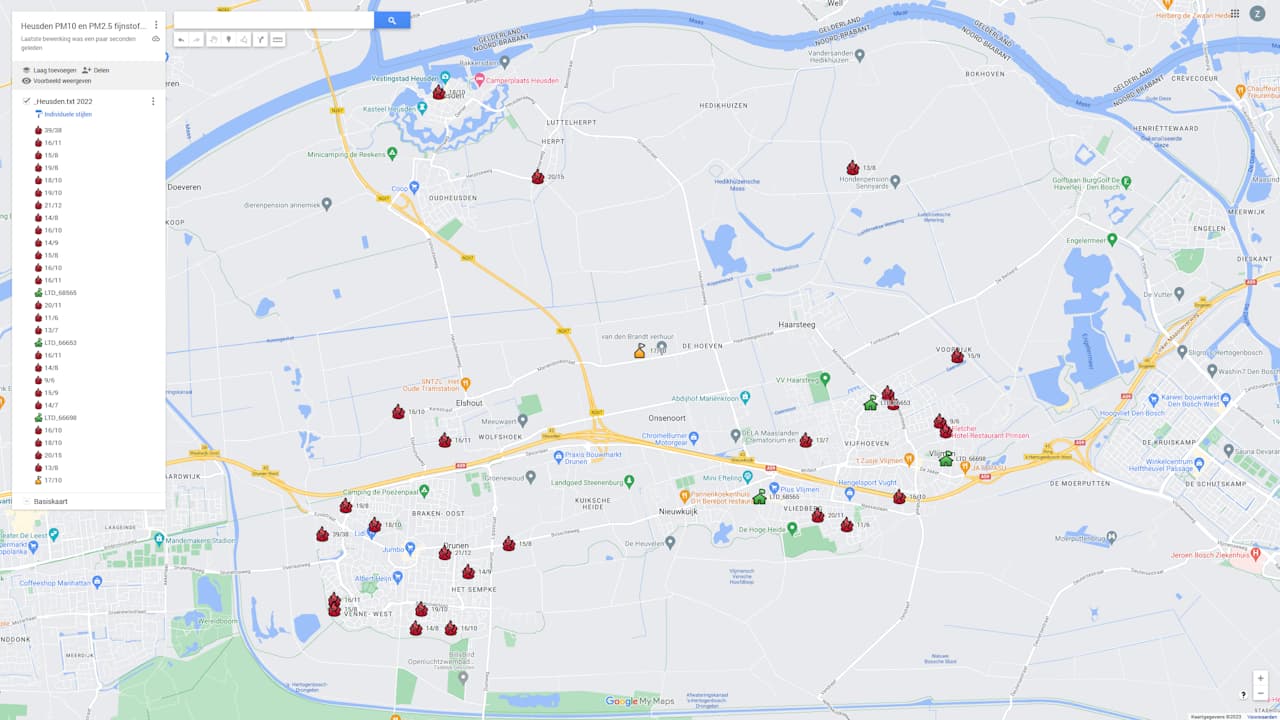
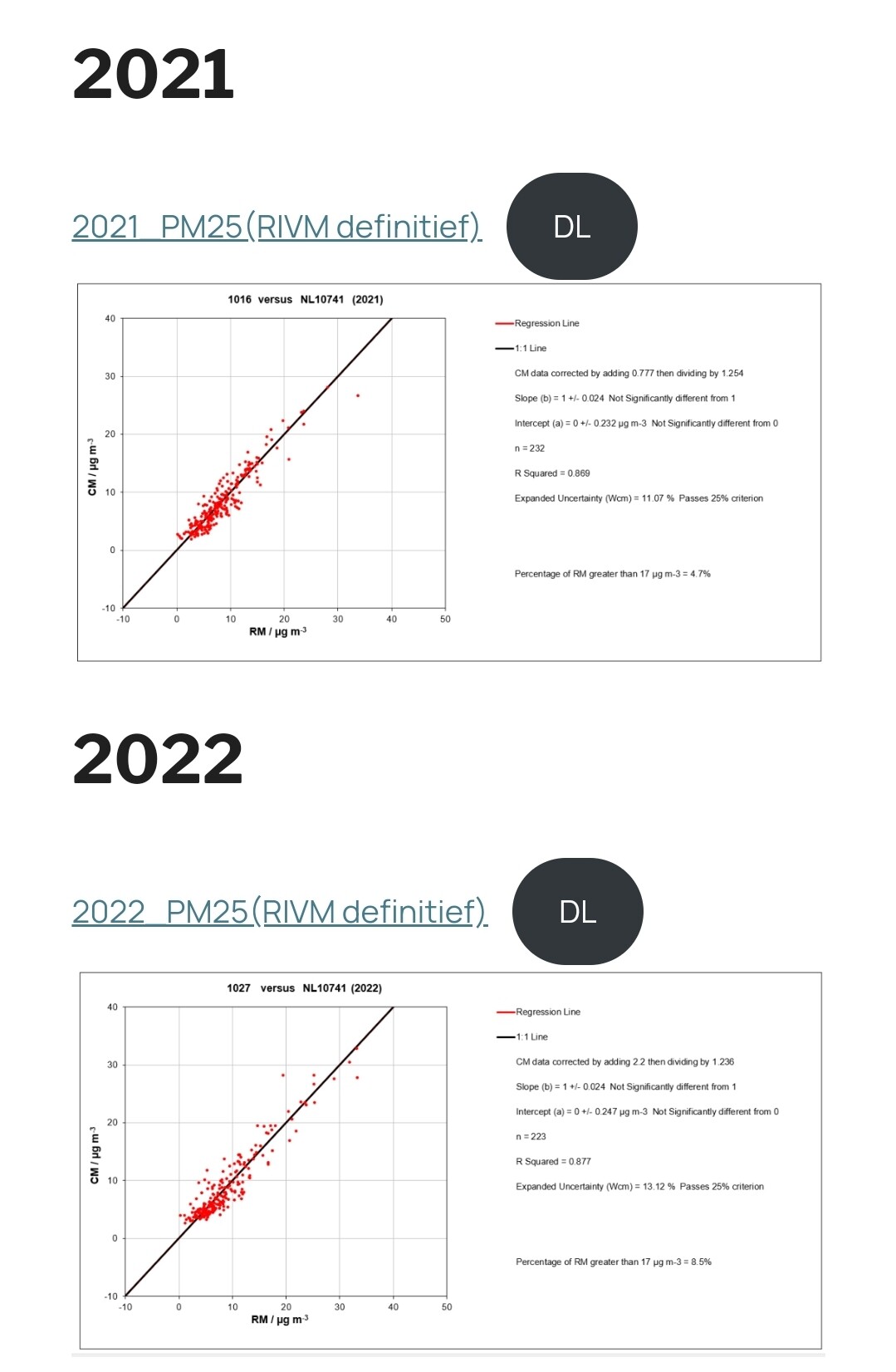
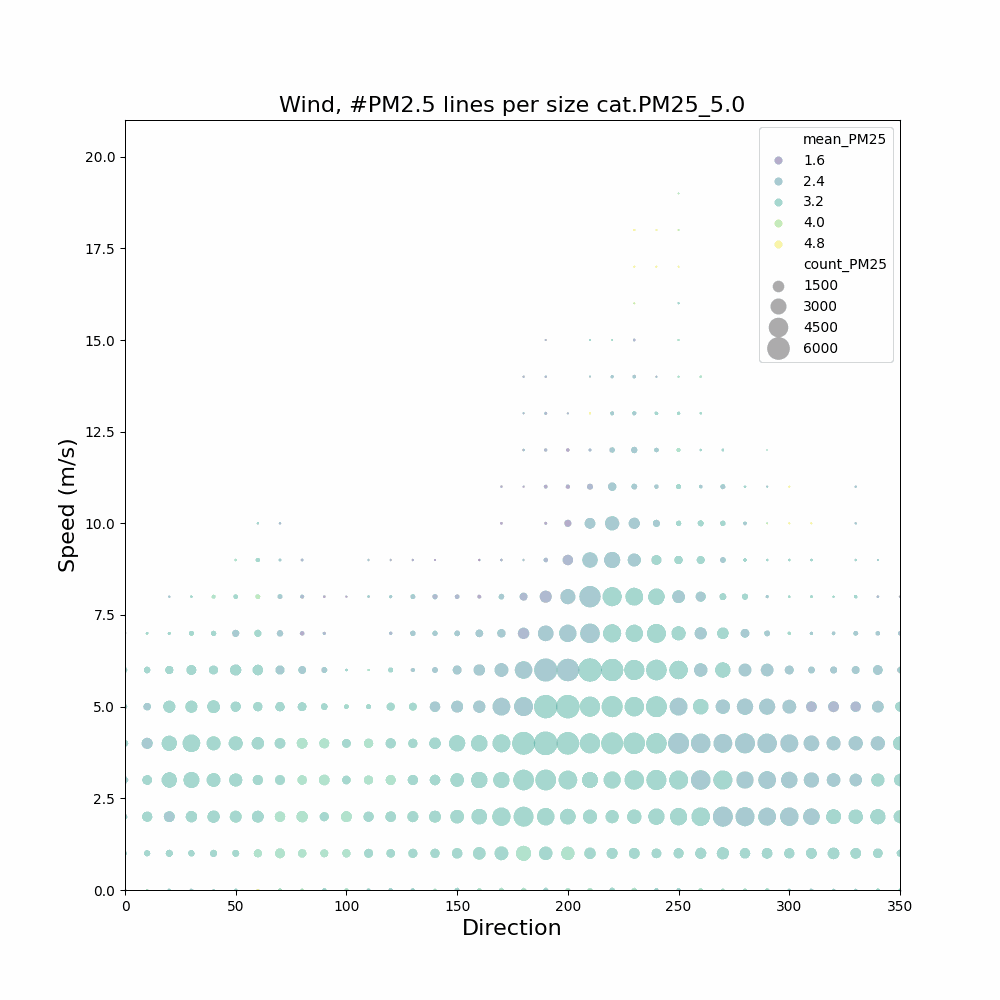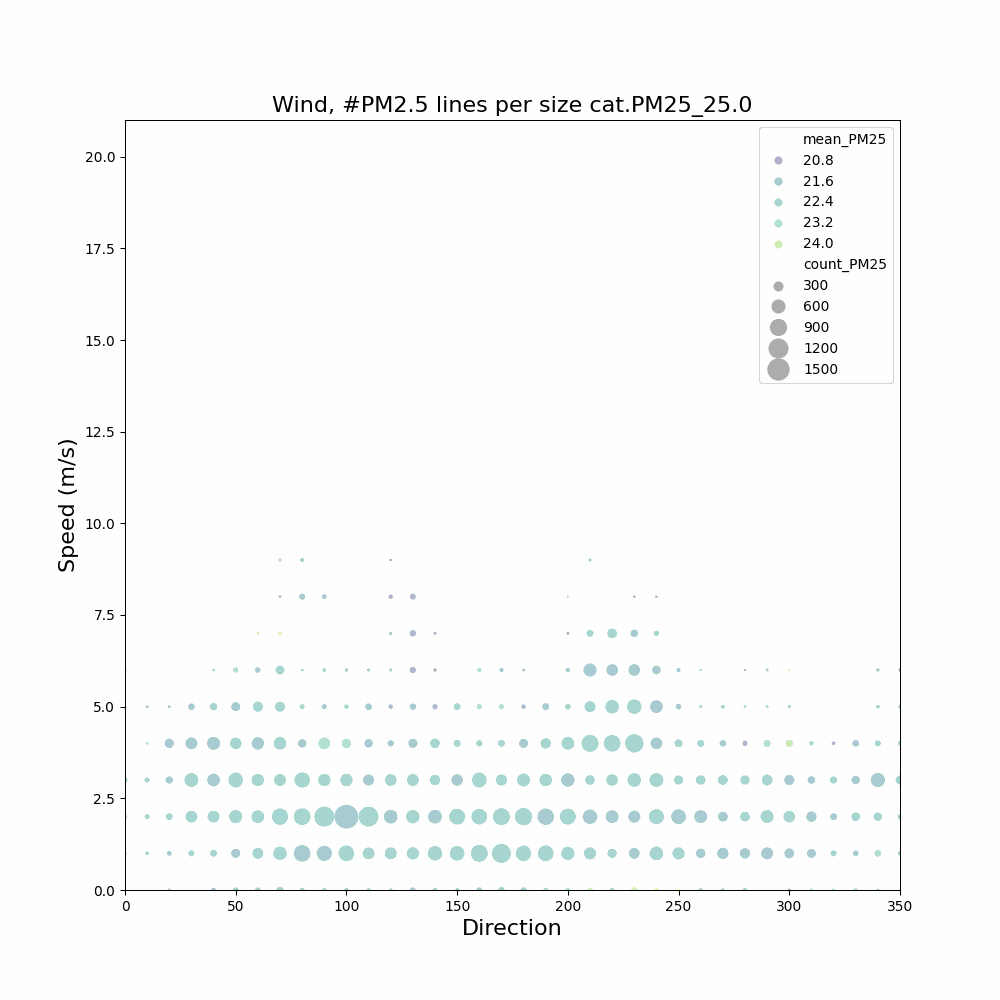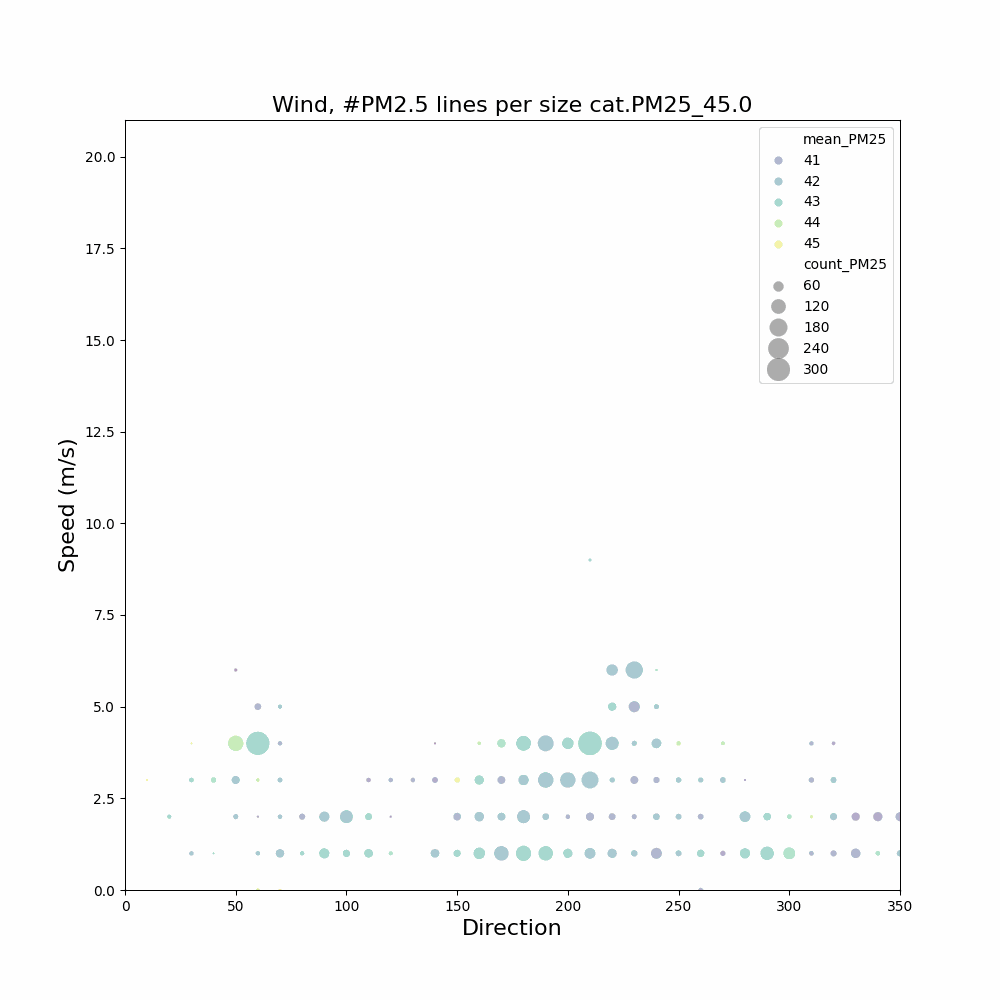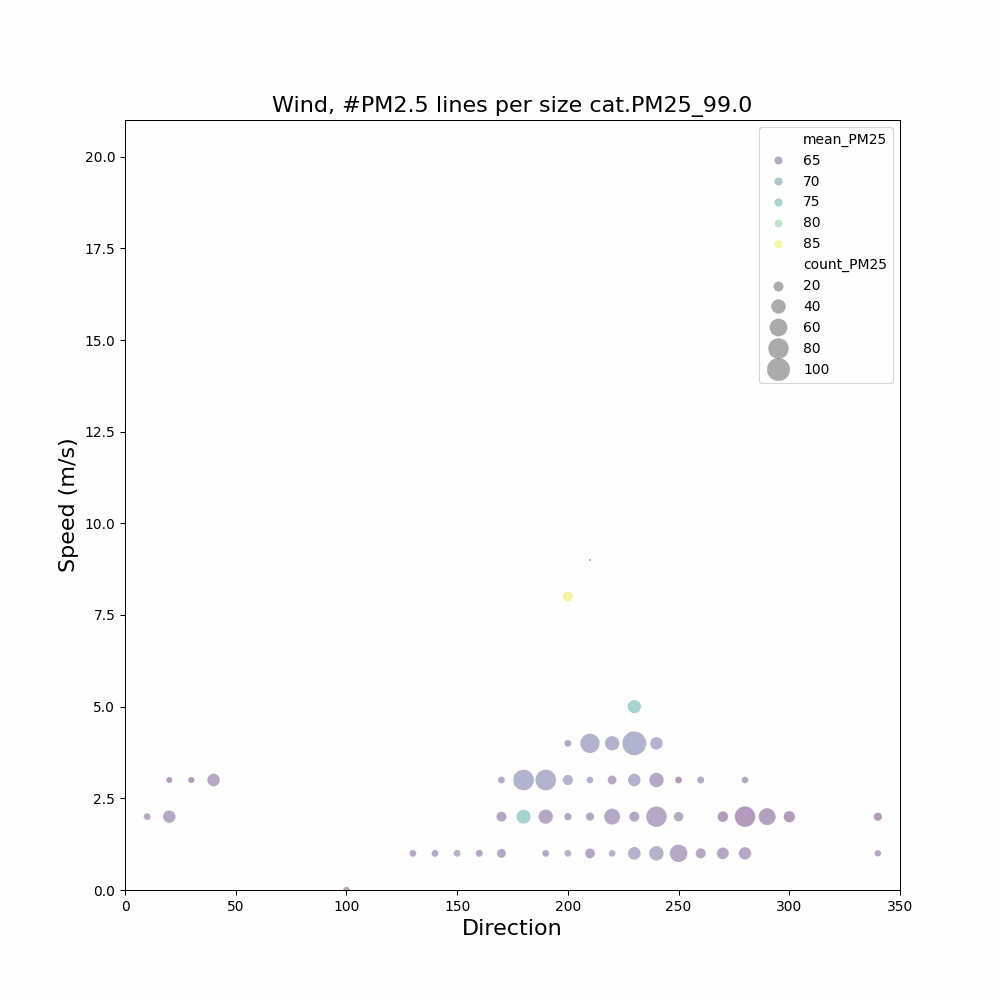
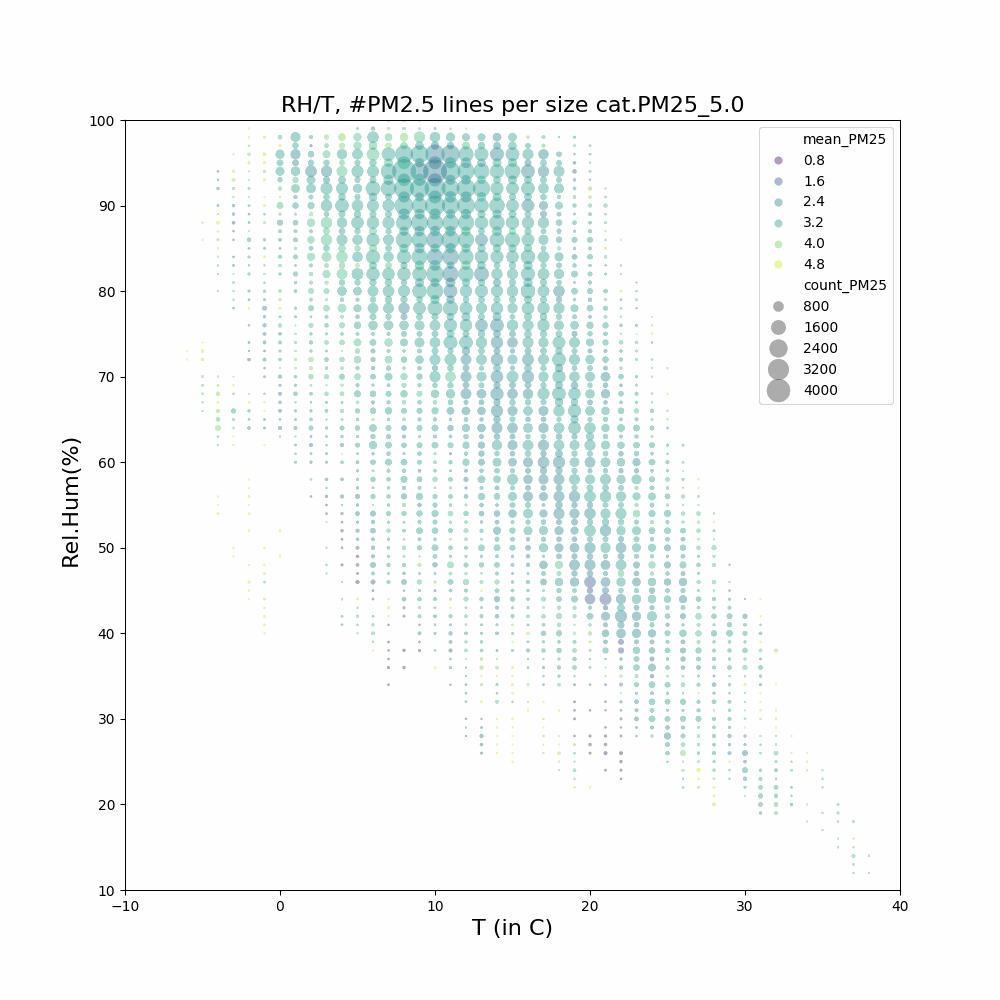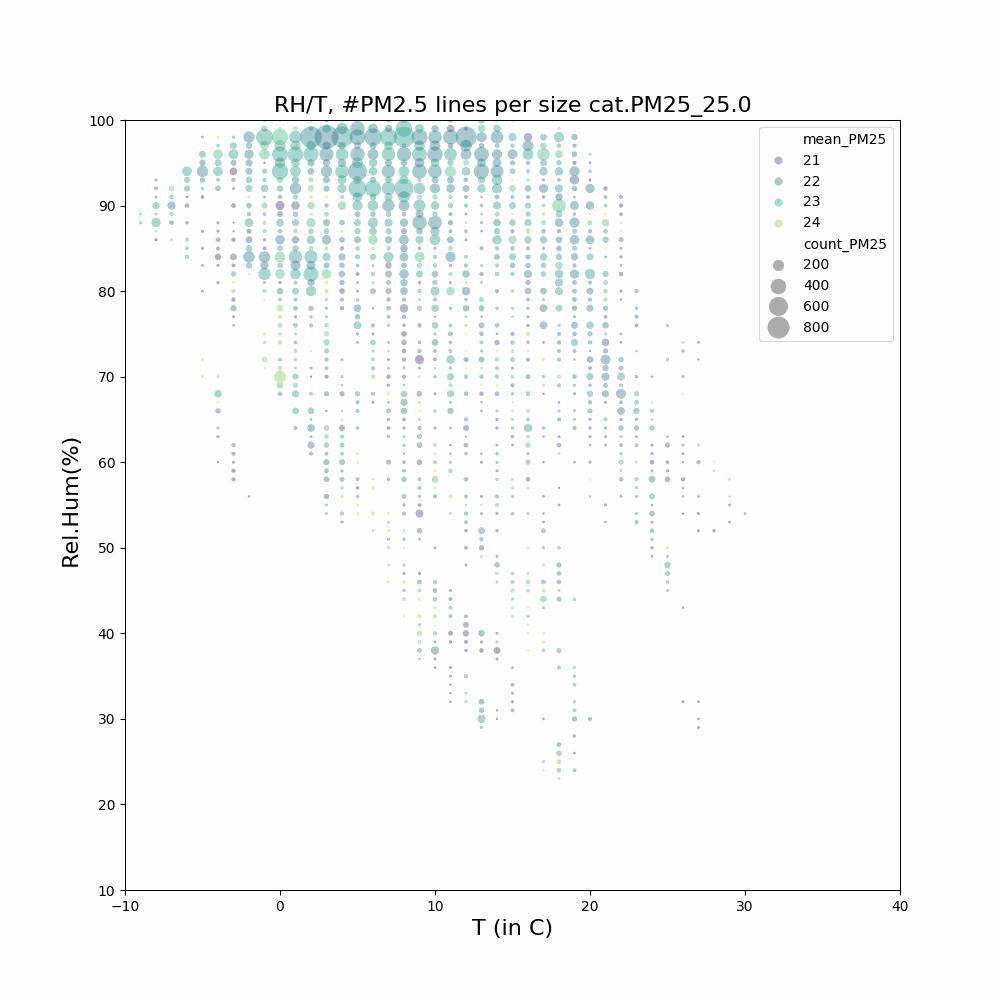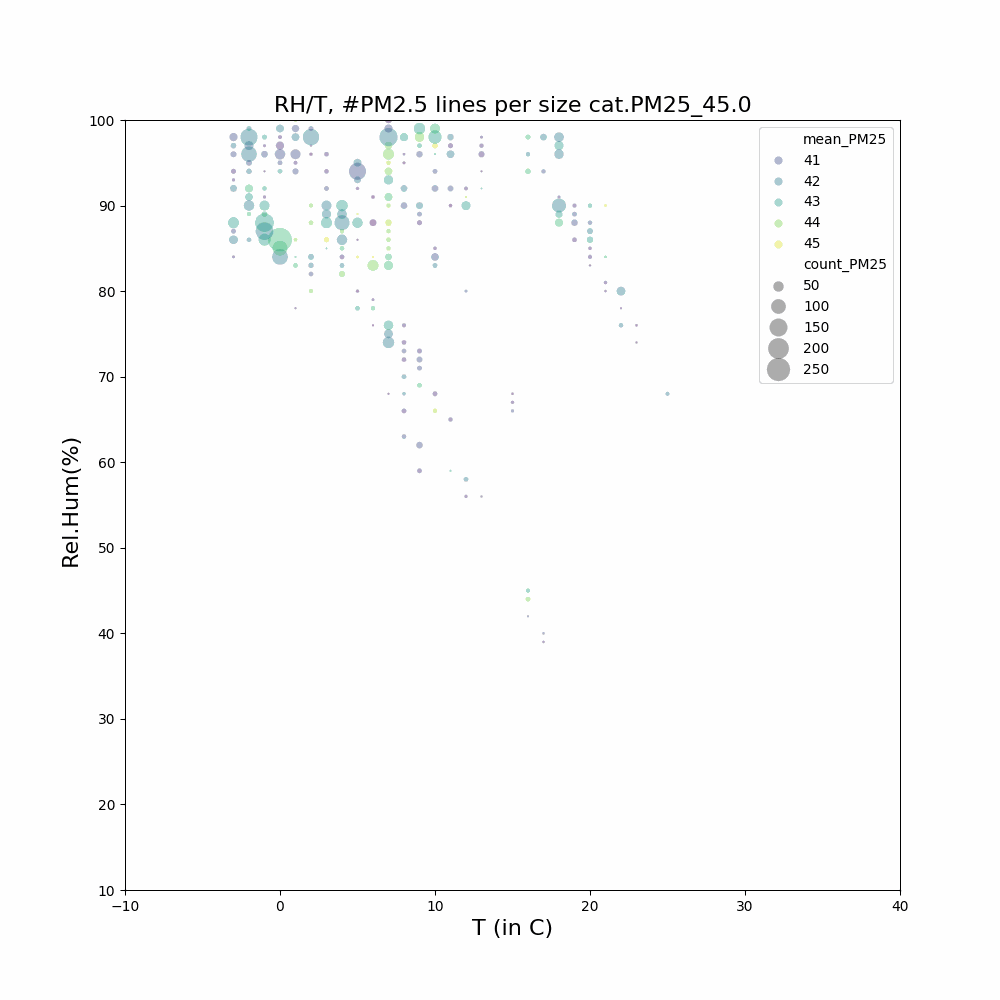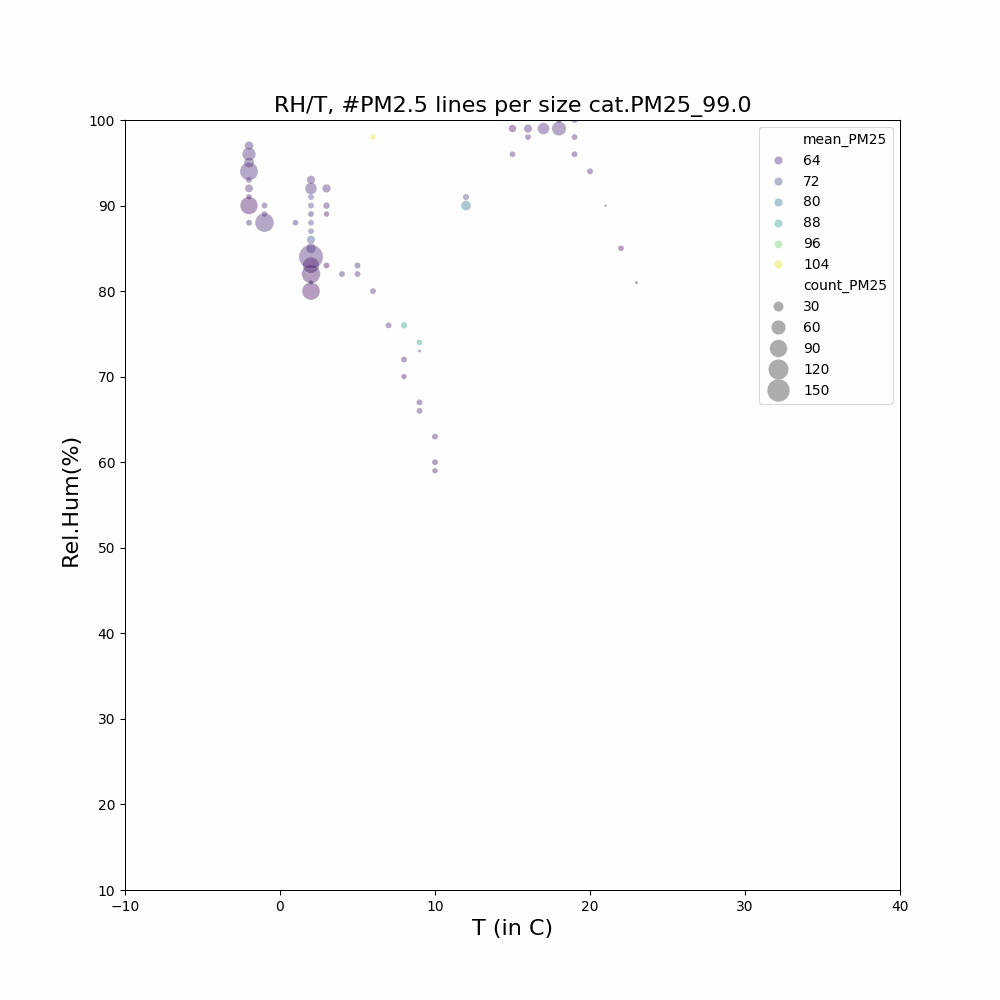Aangezien ik geïnteresseerd ben in het feit dat in de wintermaanden en bepaalde uren er mogelijk meer last van houtstook is, heb ik filteropties toegevoegd: [j2000-3000] [m1-12] [u0-23]
Gebruik : python samenvatting.py STATION_LIJST.txt
Voorbeeld: python samenvatting.py _heusden.txt
Opties : [uur] [dag] [week] [maand] [j2000-3000] [m1-12] [u0-23]
Opm.1: Wilt u meer details zien, gebruik parameter uur/dag/week/maand
Opm.2: Wilt u alleen bepaalde jaren mee te nemen,
kunt u filteren met optie [j2000-3000]:
bijvoorbeeld alleen jaren 2021 tot en met 2022: j2021-2022
Opm.3: Wilt u alleen bepaalde maanden mee te nemen,
kunt u filteren met optie [m1-12]:
bijvoorbeeld alleen de maanden november tot en met maart: m11-3
Opm.4: Wilt u alleen bepaalde uren mee te nemen,
kunt u filteren met optie [u0-23]:
bijvoorbeeld alleen de uren van 18:00 tot en met 02:00: u18-2
Opm.5: station namen van een gemeente kan opgevraagd worden met tool:
python gemeente_station_namen.py gemeente_code
Opm.6: Voordat dit script gedraaid wordt, moeten de .csv bestanden voor
deze STATION_LIJST.txt gegenereerd zijn met:
python station_data_naar_csv.py STATION_LIJST.txt
Voor gemeente Heusden geeft dit hogere gemiddelde waardes voor de wintermaanden en avonduren.
Voorbeelden voor gemiddeldes…
python ..\samenvatting.py j2022-2022 _GemeenteHeusden.txt|egrep "Datum|Gemiddelde"
Station, Periode, Datum, Info, PM10, (Min, Max, #WHO, #EU), PM2.5, (Min, Max, #WHO), Commentaar
Gemiddelde, JAAR, 2022-01-01, 2022, 16, 0, 1000, 12, 12, 11, 0, 1000, 144, PM10 > WHO jaar 15; PM2.5 > WHO jaar 5
PM10 is gemiddeld 16 en PM2.5 is gemiddeld 11 voor jaar 2022
python ..\samenvatting.py j2022-2022 m11-3 _GemeenteHeusden.txt|egrep "Datum|Gemiddelde"
Station, Periode, Datum, Info, PM10, (Min, Max, #WHO, #EU), PM2.5, (Min, Max, #WHO), Commentaar
Gemiddelde, JAAR, 2022-01-01, 2022, 18, 0, 1000, 10, 8, 13, 0, 1000, 85, PM10 > WHO jaar 15; PM2.5 > WHO jaar 5
PM10 is gemiddeld 18 (2 hoger) en PM2.5 is gemiddeld 13 (2 hoger) voor jaar 2022 van november tot en met maart.
python ..\samenvatting.py j2022-2022 u18-3 _GemeenteHeusden.txt|egrep "Datum|Gemiddelde"
Station, Periode, Datum, Info, PM10, (Min, Max, #WHO, #EU), PM2.5, (Min, Max, #WHO), Commentaar
Gemiddelde, JAAR, 2022-01-01, 2022, 17, 0, 1000, 18, 13, 10, 0, 1000, 124, PM10 > WHO jaar 15; PM2.5 > WHO jaar 5
PM10 is gemiddeld 17 (1 hoger) en PM2.5 is gemiddeld 10 (1 lager) voor jaar 2022 van 18:00 tot en met 04:00 uur
python ..\samenvatting.py j2022-2022 m11-3 u18-3 _GemeenteHeusden.txt|egrep "Datum|Gemiddelde"
Station, Periode, Datum, Info, PM10, (Min, Max, #WHO, #EU), PM2.5, (Min, Max, #WHO), Commentaar
Gemiddelde, JAAR, 2022-01-01, 2022, 19, 0, 789, 16, 13, 13, 0, 789, 90, PM10 > WHO jaar 15; PM2.5 > WHO jaar 5
PM10 is gemiddeld 19 (3 hoger) en PM2.5 is gemiddeld 13 (2 hoger) voor jaar 2022 van november tot en met maart en 18:00 tot en met 03:00 uur